Ácidos nucleicos
 Un
organismo vivo contiene un conjunto de instrucciones para cada paso necesario
para formar una réplica de sí mismo. Esa información reside en el material
genético o genoma del organismo. Los genomas de todas las células están
formados por ADN. Algunos genomas virales están formados por ARN. Un genoma puede
consistir en una sola molécula de ADN, como en muchas especies de bacterias.
Un
organismo vivo contiene un conjunto de instrucciones para cada paso necesario
para formar una réplica de sí mismo. Esa información reside en el material
genético o genoma del organismo. Los genomas de todas las células están
formados por ADN. Algunos genomas virales están formados por ARN. Un genoma puede
consistir en una sola molécula de ADN, como en muchas especies de bacterias.
En los
eucariotas, el genoma es un conjunto completo de moléculas de ADN que se
encuentran en el núcleo (es decir, el conjunto haploide de cromosomas en los
organismos diploides). Por convención, el
genoma de una especie no incluye ADN mitocondrial y de cloroplastos. Con raras
excepciones, no hay dos individuos en una especie que tengan exactamente la
misma secuencia del genoma.
La información que especifica la
estructura primaria de una proteína está codificada en la secuencia de
nucleótidos en el ADN. Esta información se copia enzimáticamente durante la
síntesis de ARN, en el proceso llamado transcripción. Algo de la información
contenida en las moléculas transcritas de ARN se traduce o traslada durante la
síntesis de cadenas de polipéptidos, que se doblan y se ensamblan entonces para
formar moléculas de proteína. Así, se puede generalizar que la información
biológica guardada en el ADN de una célula pasa del ADN al ARN y a la proteína.
Nucleótidos
Los ácidos nucleicos son
polinucleótidos, o polímeros de nucleótidos. Los nucleótidos tienen tres
componentes: un azúcar con cinco carbonos, uno o más grupos fosfato y un
compuesto nitrogenado débilmente básico llamado base. Las bases que se
encuentran en los nucleótidos son pirimidinas y purinas sustituidas. La pentosa
suele ser ribosa (D-ribofuranosa) o 2-desoxirribosa (2-desoxi-D-ribofuranosa).
Los N-glicósidos pirimidina o purina de estos azúcares se llaman
nucleósidos. Los nucleótidos son los ésteres de fosfato de los nucleósidos; los
nucleótidos comunes contienen uno a tres grupos fosforilo. Los nucleótidos que
contienen ribosa se llaman ribonucleótidos, y los que contienen desoxirribosa
se llaman desoxirribonucleótidos.

Ø
Ribosa y desoxirribosa:
Los dos azúcares aparecen como
proyecciones de Haworth de la configuración b de las formas de anillo de
furanosa. Es la configuración estable que existe en los nucleótidos y
polinucleótidos. Cada uno de esos anillos de furanosa puede adoptar
conformaciones diferentes. La conformación de la desoxirribosa predomina en el ADN
de doble hebra.

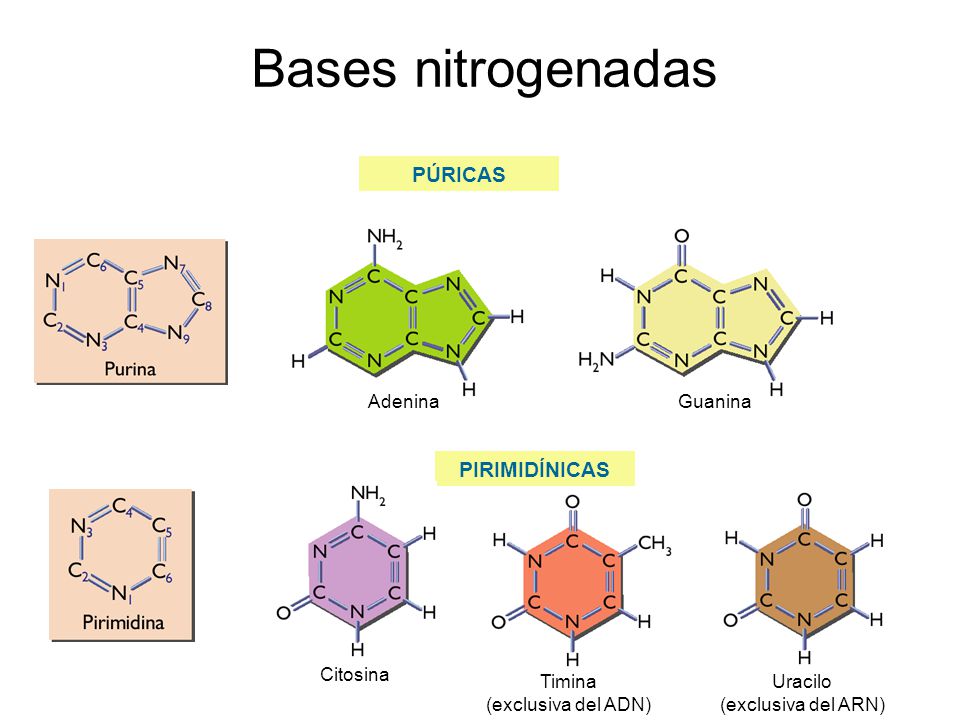
Ø Purinas y pirimidinas:
Las
bases que se encuentran en los nucleótidos son derivados de pirimidina o de
purina.
La
pirimidina tiene un solo anillo de cuatro átomos de carbono y dos de nitrógeno.
La purina tiene un sistema de anillos fundidos de pirimidina y de imidazol. Los
dos tipos de bases son no saturados, con dobles enlaces conjugados. Esta
propiedad hace que los anillos sean planos, y también explica su capacidad de
absorber la luz ultravioleta. Las purinas y pirimidinas sustituidas son ubicuas
en las células vivas, pero casi nunca se encuentran las bases no sustituidas en
los sistemas biológicos. Las principales pirimidinas que hay en los nucleótidos
son uracilo (2,4-dioxopirimidina, U), timina (2,4-dioxo-5-metilpirimidina, T) y
citosina (2-oxo-4-aminopirimidina, C). Las principales purinas son adenina
(6-aminopurina, A) y guanina (2-amino-6-oxopurina, G). La adenina, la guanina y
la citosina están en ribonucleótidos y desoxirribonucleótidos. El uracilo se
encuentra principalmente en ribonucleótidos y la timina en
desoxirribonucleótidos. Las purinas y las pirimidinas son bases débiles relativamente
insolubles en agua al pH fisiológico. Sin embargo, dentro de las células la mayor
parte de bases pirimidina y purina se encuentran como constituyentes de
nucleótidos y polinucleótidos, compuestos que son muy hidrosolubles.
Cada base heterocíclica de los
nucleótidos comunes puede existir cuando menos en dos formas tautómeras. La
adenina y la citosina (que son amidinas cíclicas) pueden existir en sus formas
amino o imino, y la guanina, timina y uracilo (que son amidas cíclicas) pueden
existir en forma de lactama (ceto) o de lactima (enol). Las formas tautómeras
de cada base existen en equilibrio, pero los tautómeros amino y lactama son más
estables, y en consecuencia predominan bajo las condiciones que hay en el
interior de la mayoría de las células. Los anillos permanecen no saturados y
planos en cada tautómero.
Los nucleótidos son derivados
fosforilados de los nucleósidos. Los ribonucleósidos contienen tres grupos
hidroxilo que se pueden fosforilar (2_, 3_ y 5_), y los desoxirribonucleósidos contienen
dos de esos grupos hidroxilo (3_ y 5_). En los nucleótidos naturales, los
grupos fosforilo suelen estar unidos al átomo de oxígeno del grupo 5_-hidroxilo.
Por convención, siempre se supone que un nucleótido es un éster de 5_-fosfato,
a menos que se indique otra cosa.
Los nombres sistemáticos de los
nucleótidos indican la cantidad de grupos fosfato presentes. Por ejemplo, el
éster 5_-monofosfato de la adenosina se llama adenosina monofosfato (AMP).
También se le llama sólo adenilato. De igual modo, el éster 5_-monofosfato de
la desoxicitidina se puede llamar desoxicitidina monofosfato (dCMP) o
desoxicitidilato. El éster 5_-monofosfato del desoxirribonucleósido de timina
se conoce como timidilato, pero a veces se le llama desoxitimidilato, para
evitar ambigüedades.
Nucleósidos
Los nucleósidos están formados por
ribosa y desoxirribosa y una base heterocíclica. En cada nucleósido, un enlace b-N-glicosídico
conecta el C-1 del azúcar al N-1 de la pirimidina o
al N-9 de la purina.
Por consiguiente, los nucleósidos son derivados N-ribosilo o N-desoxirribosilo
de las pirimidinas o las purinas. La convención de numeración para los átomos
de carbono y nitrógeno de los nucleósidos refleja que están formados por una base
y un azúcar de cinco carbonos, y cada uno de ellos tiene su propio esquema de
numeración. La designación de los átomos en las partes de purina y pirimidina
tiene preferencia.
Por consiguiente, los
átomos de las bases se numeran 1, 2, 3, etc., en tanto que los del anillo de
furanosa se diferencian por tener primas (_). Así, el enlace b-N-glicosídico
se une al átomo de C-1_, o 1_, de la parte del azúcar a la base. La ribosa y la
desoxirribosa difieren en la posición del C-2_, o.

ADN
El ADN es el almacén de la
información biológica. Cada célula contiene docenas de enzimas y proteínas que
se unen al ADN y reconocen ciertas propiedades estructurales, como la secuencia
de nucleótidos.
 En las secciones que siguen se verá
cómo la estructura del ADN permite que esas proteínas tengan acceso a la
información almacenada..La estructura primaria de un ácido nucleico es la
secuencia de sus residuos de nucleótido unidos por enlaces 3_,5_-fosfodiéster.
Un tetranucleótido que representa un segmento de una cadena de ADN ilustra esos
enlaces (figura 19.11). El esqueleto de la cadena de polinucleótidos consiste
en los grupos fosforilo y los átomos de carbono 3_, 4_ y 5_, y el átomo de oxígeno
3_ de cada desoxirribosa. Como se ve en la figura 19.10, esos átomos del
esqueleto están arreglados en una conformación extendida. Eso hace que el ADN
de doble cadena sea una molécula larga y delgada, a diferencia de las cadenas
de polipéptido que con facilidad se pueden doblar sobre sí mismas hacia atrás.
En las secciones que siguen se verá
cómo la estructura del ADN permite que esas proteínas tengan acceso a la
información almacenada..La estructura primaria de un ácido nucleico es la
secuencia de sus residuos de nucleótido unidos por enlaces 3_,5_-fosfodiéster.
Un tetranucleótido que representa un segmento de una cadena de ADN ilustra esos
enlaces (figura 19.11). El esqueleto de la cadena de polinucleótidos consiste
en los grupos fosforilo y los átomos de carbono 3_, 4_ y 5_, y el átomo de oxígeno
3_ de cada desoxirribosa. Como se ve en la figura 19.10, esos átomos del
esqueleto están arreglados en una conformación extendida. Eso hace que el ADN
de doble cadena sea una molécula larga y delgada, a diferencia de las cadenas
de polipéptido que con facilidad se pueden doblar sobre sí mismas hacia atrás.
Todos los residuos de nucleótido dentro
de una cadena de polinucleótido pueden tener la misma orientación. Entonces,
las cadenas de polinucleótido tienen direccionalidad, igual que las de
polipéptido. Se dice que un extremo de una cadena lineal de polinucleótido es 5_
(porque no hay residuo unido a su carbono 5_) y que el otro es 3_ (porque no
hay residuo unido a su átomo de carbono 3_). Por convención, la dirección de
una hebra de ADN se define leyendo los átomos que forman el residuo de azúcar.
 Así, al ir de arriba abajo de la
hebra en la figura 19.11, se define como 5_ → 3_ (“cinco prima a tres prima”)
porque se cruza el residuo de azúcar encontrando los carbonos 5_, 4_ y 3_ en
ese orden. De igual modo, al ir de abajo arriba de la hebra quiere decir
moverse en la dirección 3_ → 5_. Se supone que las abreviaturas estructurales
se leen en dirección 5_ → 3_, a menos que se indique otra cosa. Cada grupo
fosfato que participa en un enlace fosfodiéster tiene un pKa aproximado de
2, y una carga negativa a pH neutro. En consecuencia, los ácidos nucleicos son
polianiones bajo las condiciones fisiológicas. Dentro de la célula, los grupos
fosfato con carga negativa se neutralizan con pequeños cationes y con proteínas
con carga positiva.
Así, al ir de arriba abajo de la
hebra en la figura 19.11, se define como 5_ → 3_ (“cinco prima a tres prima”)
porque se cruza el residuo de azúcar encontrando los carbonos 5_, 4_ y 3_ en
ese orden. De igual modo, al ir de abajo arriba de la hebra quiere decir
moverse en la dirección 3_ → 5_. Se supone que las abreviaturas estructurales
se leen en dirección 5_ → 3_, a menos que se indique otra cosa. Cada grupo
fosfato que participa en un enlace fosfodiéster tiene un pKa aproximado de
2, y una carga negativa a pH neutro. En consecuencia, los ácidos nucleicos son
polianiones bajo las condiciones fisiológicas. Dentro de la célula, los grupos
fosfato con carga negativa se neutralizan con pequeños cationes y con proteínas
con carga positiva.
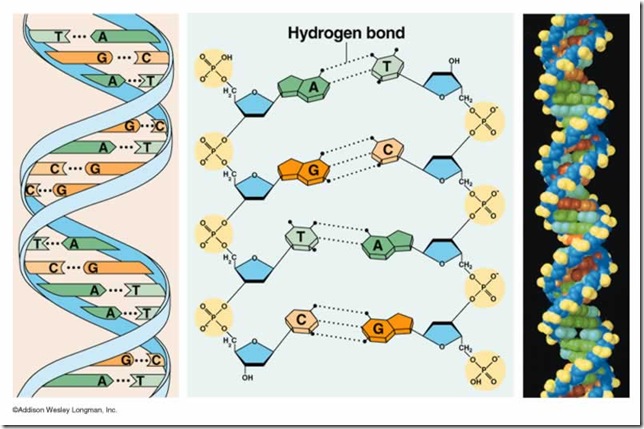
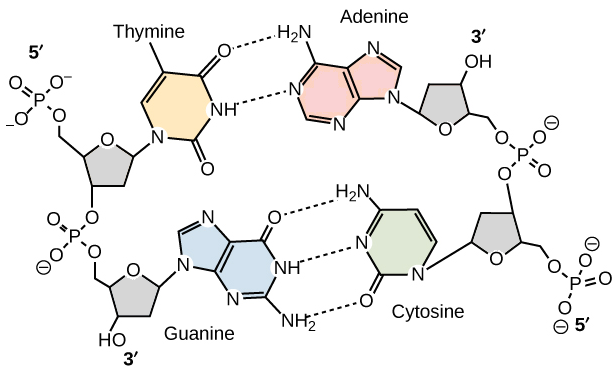
La mayor parte de las moléculas de
ADN consisten de dos hebras, de polinucleótidos. Cada una de las bases en una
hebra forma puentes de hidrógeno con una base de la hebra opuesta. Los pares de
bases más comunes están entre los tautómeros lactama y amino de las bases. La
guanina se aparea con citosina y la adenina con timina, maximizando los puentes
de hidrógeno entre sitios potenciales. Entonces, los pares de bases G/C tienen
tres puentes de hidrógeno, y los pares de bases A/T tienen dos. Esta propiedad
del ADN de doble hebra explica el descubrimiento de Chargaff, de que la
relación de A con T y de G con C es 1:1 para una gran variedad de moléculas de
ADN.
Como A en una hebra se aparea con T
en la otra, y G se aparea con C, las hebras son complementarias, y una puede
servir como plantilla para la otra. Los esqueletos de azúcar-fosfato en las
hebras complementarias de ADN de doble hebra tienen orientaciones opuestas. En
otras palabras, son antiparalelas. Cada extremo del ADN de doble hebra está
formado por el extremo 5_ de una hebra y el extremo 3_ de la otra. En el ADN de
doble hebra, la distancia entre dos esqueletos de azúcar-fosfato es igual para
cada par de bases. En consecuencia, todas las moléculas de ADN tienen la misma
estructura regular, a pesar de que puedan ser muy diferentes sus secuencias de nucleótidos.
doble hebra.
1. Interacciones de apilamiento Los pares de bases apilados forman
contactos de van der Waals. Aunque las fuerzas entre los pares de bases
individuales apilados son débiles, son aditivas, por lo que en las moléculas
grandes de ADN los contactos de van der Waals son una fuente importante de
estabilidad.

2. Puentes de hidrógeno. Los puentes de hidrógeno entre
pares de bases forman una importante fuerza estabilizadora.
3. Efectos hidrofóbicos. Al sepultar los anillos hidrofóbicos
de purina y pirimidina en el interior de la doble hélice aumenta la estabilidad
de la hélice.
4. Interacciones entre cargas. La repulsión electrostática de
los grupos fosfato con carga negativa en el esqueleto es una fuente potencial
de inestabilidad de la hélice de ADN. Sin embargo, la repulsión se minimiza por
la presencia de cationes como y proteínas catiónicas (que contienen abundancia
de los residuos básicos arginina y lisina).

Superenrollamiento
Transcripción y procesamiento del ADN
Tipos de ARN
Las moléculas de ARN participan en
varios procesos asociados a la expresión génica.
Esas moléculas se encuentran en
copias múltiples y en varias formas distintas dentro de una célula dada. Hay
cuatro clases principales de ARN en todas las células vivas:
1. ARN ribosómico (ARNr); moléculas que son parte
integral de los ribosomas (ribonucleoproteínas intracelulares que son sitios de
síntesis de proteínas). El ARN ribosómico es la clase más abundante de ácido ribonucleico,
que forma 80% del ARN celular total.
2. ARN de transferencia (ARNt); son moléculas que llevan a
los aminoácidos activados a los ribosomas para su incorporación a las cadenas
de péptidos en crecimiento durante la síntesis de proteínas. Las moléculas de
ARNt sólo tienen de 73 a 95 residuos de nucleótidos de longitud. Forman un 15%
del ARN celular total.
3. ARN mensajero(ARNm); moléculas que codifican las
secuencias de aminoácidos en las proteínas. Son los “mensajeros” que llevan la
información del ADN al complejo de traducción, donde se sintetizan las
proteínas. En general, el ARNm sólo forma el 3% del ARN celular total. Estas
moléculas son las menos estables de los ácidos ribonucleicos celulares.
4. ARN pequeño; moléculas presentes en todas las
células. Algunas moléculas pequeñas de ARN tienen actividad catalítica o
contribuyen a la actividad catalítica, asociadas a proteínas. Muchas de esas
moléculas de ARN se relacionan con eventos de procesamiento que modifican al
ARN después de que se ha sintetizado.


Comentario de los videos:
Replicación: es muy importante esta etapa porque gracias a ella se puede obtener una hebra identica a otra en el ADN, esta tiene varias etapas:
- El ADN se desenrrolla y se rompen los puentes de hidrógeno, la helicasa ayuda en este proceso.
- Hay proteínas que se enlazan a cada cadena sencilla para que no se vuelvan a unir y se crea la burbuja de replicación (se froman en varios lugares a lo largo de la molecula de ADN).
- Una vez formado esto, se forma una horquilla de replicación. Entonces la DNA polimerasa comienza a construir a una nueva cadena. La construye en dirección 5´ 3´.
- La DNA polimerasa no pude iniciar la nueva cadena, solo prolonga una nueva preexistente. Actúan aquí, la RNA primasa que es la que colocara los nucleótidos complementarios de la cadena en el transcurso de la DNA polimerasa. El RNA cebador en este caso proporciona un extremo 3´ libre al que enlazarse. entonces la DNA polimerasa comienza a colocar los nucleótidos complementarios.
- La hélice continua desenrrollandose y la DNA polimerasa, en compañía de los ya mencionados RNA continúan el proceso de replicación.
- Un tpo diferente de DNA polimerasa reemplaza al cebador RNA por DNA.
- En la otra horquilla se comienza también el proceso de replicación.
Finalmente se obtienen dos moléculas completas de DNA.
Transcripción:
Es el proceso por el cual en ADN se copia a ARN en la primera etapa de la expresión génica.
Aquí se da el ensamblaje de varios factores en el inicio del gen. Entre estos factores están:
RNA polimerasa quien durante cierto tiempo esta unida al complejo pero de un momentos a otro es liberada y se desplaza rapidamente por la cadena de ADN leyendo el gen, para leerla debe desenrrollar la doble hélice y al mismo tiempo copia una de ellas, esta copia es el RNA, para poder hacer esta copia hay nucleótidos que entran a través de la RNA polimerasa por medio de un tunel, que es el centro activo de la enzima y estos se aparean nucleótido a nucleótido copiando la A, G Y T del gen, la diferencia es que las timinas son reemplazadas por Uracilos.
Traducción:
Esta presente un ARN mensajero, este tiene una cola poliA- tail, y tiene codones que codifican aminoácidos específicos, y al final una capa metilada.
Esta molécula lo que hace es llevar esta información del núcleo a un ribosoma para producir una proteína específica que el gen codifica.
El ribosoma tiene una unidad grande y otra pequeña, que se arma sobre el ARN mensajero.
La unidad pequeña se une al RNA mensajero y se una al punto de iniciación (donde comienzan los codones), los aminoácidos son llevados al ribosoma gracias a RNA de transferencia específico.
RNA de transferencia tiene un anticodón que es complementario al codón de ARN mensajero.
La unidad pequeña posiciona al ARN mensajero para que pueda ser leído en grupo de tres aminoácidos, es decir los codones.
La unidad grande remueve cada aminoácido y lo une a la cadena creciente.
A medida que se da el proceso, la secuencia de codones es traducida y convertida en secuencia de aminoácidos.
Cada RNA de transferencia tiene en su punta un aminoácido que, cuando se lee el codón, se libera y se une a un segundo aminoácido que se encuentre en el ARN de trsnferencia que se encuentra detrás del primero, y así se van uniendo aminoácido tras aminoácido. Tras haber completado la cadena, un factor de liberación entra en acción y se libera la proteína formada.
Empaquetamiento del ADN
No hay comentarios:
Publicar un comentario